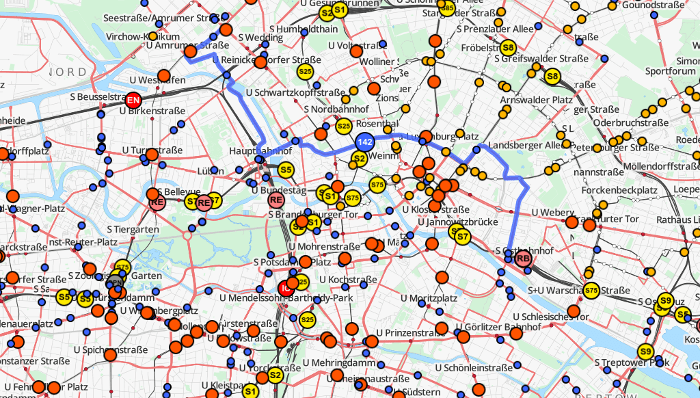
Mapping von Netzen des öffentlichen Verkehrs
Vor einigen Monaten ging der von geOps und der Universität Freiburg entwickelte weltweite ÖNV-Tracker TRAVIC online. Für die Visualisierung der Fahrten verwenden wir einen Ansatz, der statische Fahrplandaten und Echtzeit-Verspätungsdaten (beides im GTFS-Format) miteinander kombiniert und daraus die Position eine Fahrzeugs interpoliert.
Dieses Vorgehen kann nur dann erfolgreich sein, wenn neben dem zeitlichen Ablauf einer Fahrt (Abfahrts- und Ankunftszeiten) auch der räumliche Verlauf annähernd genau bekannt ist. Das GTFS-Format sieht zwar die genauen Koordinaten von Haltepunkten als verpflichtendes Feld vor, definiert die exakten Fahrtverläufe (Shapes) zwischen den Stationen jedoch als optionale Angabe. Dies hat zur Folge, dass Fahrzeuge nicht dem Straßen bzw. Schienennetz folgen, sondern von einer Station zur nächsten fliegen.
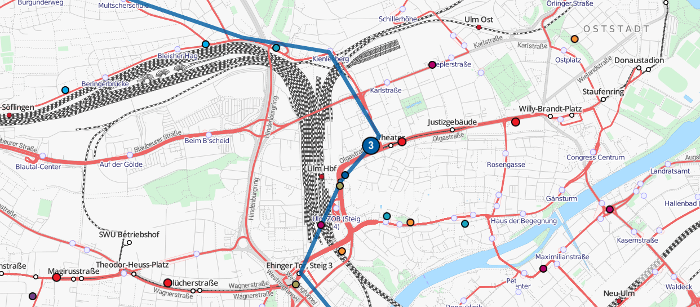
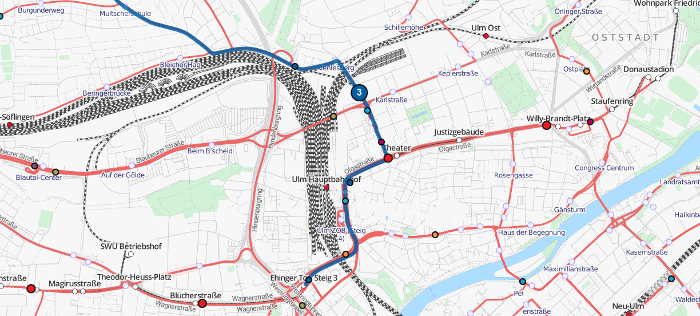
Spätestens mit der Einbindung der ÖNV-Netze der Schweiz konnte dieses Problem nicht mehr als einfacher Schönheitsfehler abgetan werden. Die Rohdaten der Verkehrsunternehmen, aus denen wir regelmäßig GTFS-Feeds generieren, enthalten außer den Positionen der Haltestellen aber keine weiteren räumlichen Angaben.
Extrahierung von Fahrverläufen aus Geodaten
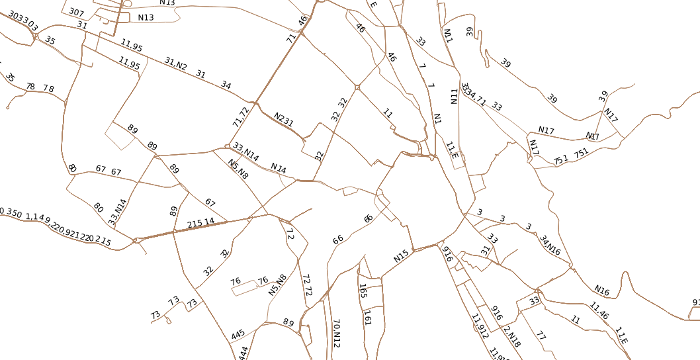
Versuche, die Menge der Schienenverkehrs-Relationen in OpenStreetMap über Ähnlichkeitsmaße (z.B. die Fréchet-Distanz) mit den Station-zu-Station-Liniengeometrien von Zugfahrten im GTFS-Feed zu vergleichen, lieferten keine brauchbaren Ergebnisse. Dass die Extrahierung der Shapes selbst für räumlich eng begrenzte Gebiete keine triviale Aufgabe ist, zeigt das (bereits in einen Graph überführte) OSM-Straßennetz von Zürich.
Unser Ansatz generiert (wahrscheinliche) Fahrtverläufe mithilfe von iterativen Shortest-Path-Aufrufen auf dem gesamten Nahverkehrsnetz. Selbstverständlich ist nicht garantiert, dass Fahrzeuge zwischen 2 Stationen immer den (im Modell) optimalen Weg nehmen. Vor allem im Schienennetz ist der kürzeste Weg oft der falsche. Daher sind gute Heuristiken nötig, um wahrscheinliche von unwahrscheinlichen Fahrtwegen unterscheiden zu können.
Die grundlegende Ablauf unseres Ansatzes ist wie folgt:
- Aufbau eines Graphen aus z.B. Schienen- oder Straßengeometrien und Einsortieren der Stationen aus dem GTFS-Feed
- Iteratives Durchgehen sämtlicher Fahrten im GTFS-Feed, Berechnung des kürzesten Weges zwischen zwei aufeinanderfolgenden Stationen
- Prüfung auf Plausibilität
- Filtern und Komprimieren der Geometrien zur Vermeidung von Redundanz
Im folgenden werden die einzelnen Schritte kurz erläutert.
1. Graph
Um eine Routenfindung auf den geografischen Referenzdaten durchführen zu können, müssen diese (häufig nur eine lose Sammlung von Liniengeometrien) in einen topologisch korrekten Graphen überführt und mit dem Fahrplan verknüpft werden. In einem ersten Schritt bereinigen wir deshalb die Ausgangsdaten von Lücken im Netz und verbinden Knoten, die jeweils nur eine ausgehende Kante haben und deren Distanz unter einem Maximalwert liegt.
Die eigentliche Verknüpfung mit den Fahrplandaten erfolgt, indem die im Fahrplan definierten Stationen in den generierten Graph eingefügt werden. Dieser Schritt ist nicht trivial. Eine einfache Verknüpfung von Fahrplanstationen und z.B. in OSM markierten Stationen ist im Allgemeinen nicht möglich und auch nicht sinnvoll, da wir auch Referenz-Geodaten nutzen können wollen, die keine Stationsinformationen enthalten. Im Fall von OpensStreetMap liegen außerdem vor allem im ländlichen Raum Bus- und Bahnstationen häufig als verwaiste Knoten außerhalb des Netzes. Selbst wenn im städtischen Raum z.B. Bus- oder Tramstationen korrekt in das Netz eingepflegt sind, ist die Korrelation mit den häufig ungenau positionierten Stationen aus den Fahrplandaten nicht einfach. Eine Zuordnung ausschließlich nach Nähe scheitert z.B. im Großstädten meist an der schieren Dichte der Stationen, nur die wenigsten Stationen sind mit einer ID versehen, die jener aus den Fahrplandaten entspricht. Die Schwierigkeiten des Vergleiches der Stationsnamen zeigt das Beispiel der möglichen Schreibweisen einer (fiktiven) Busstation "Gießstraße".
- Gießstraße
- Gießstrasse
- Giessstrasse
- Gießstr.
- Giessstr.
- Mühlenheim, Gießstraße
- Großdorf-Mühlenheim, Gießstraße
- Großdorf (Baden), Mühlenheim, Gießstraße
- Großdorf, Baden, Mühlenheim, Gießstr.
- Gießstraße (Mühlenheim)
- usw.
Die Benennung von Stationen in OSM folgt keinem exakten Schema. Auch die Benennung der Stationen in den Fahrplandaten unterscheidet sich von GTFS-Feed zu GTFS-Feed und ist teilweise nicht einmal innerhalb eines Feeds einheitlich.
Da das korrekte Einfügen der Stationen von grundlegender Bedeutung für die Qualität des Ergebnisses ist, wird die Position einer Station im Graphen in einem mehrstufigen Verfahren bestimmt. Eine Umkreissuche bestimmt zunächst die am nächsten liegenden im Ausgangsdatensatz als Station markierten Knoten. Diese Knoten werden in einer priority queue nach der Wahrscheinlichkeit ihrer Korrektheit sortiert, und zwar anhand der Kriterien Übereinstimmung der Stations-ID (wenn in korrektem Format vorhanden), Nähe und Ähnlichkeit des Stationsnamens. Findet sich innerhalb eines bestimmten Umkreises kein solcher Knoten (weil die Station in den Referenzdaten z.B. nicht vorkommt), so werden die Kanten der Umgebung analysiert, ebenfalls nach der Wahrscheinlichkeit ihrer Korrektheit geordnet (Anhand von Distanz des auf die Kante projezierten Punktes zum Punkt selbst, Rang der Kante (z.B. Wohngebietsstraße vs. Hauptstraße) und auf den Kanten als verkehrend eingetragene Fahrzeuge) und die Station auf die wahrscheinlichste Kante gesnappt. Eine Busstation wird z.B. im Fall von OSM-Daten eher auf eine Straße gesnappt, die Teil einer Bus-Relation ist, selbst wenn diese Straße weiter entfernt ist als z.B. eine kleine Seitengasse.
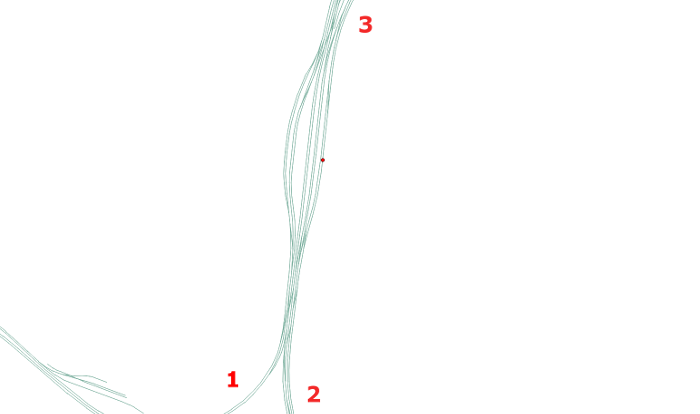
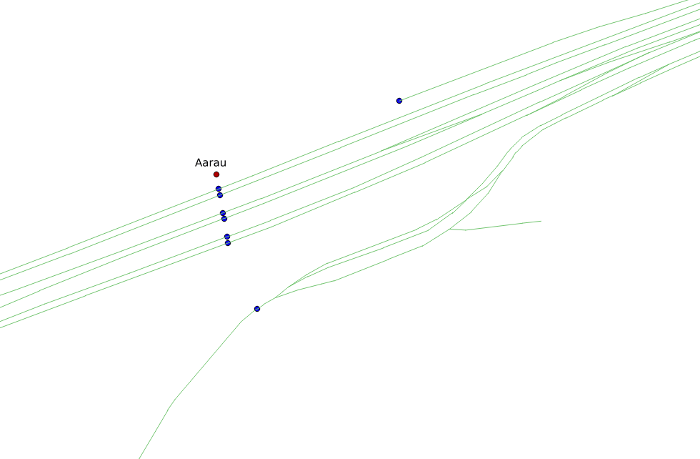
In den meisten Fällen besteht eine Station jedoch aus mehreren Haltepunkten. Dieses Problem scheint auf den ersten Blick kosmetischer Natur zu sein. Selbst im Busnetz ist eine korrekte Platzierung der Sekundärstationen jedoch von grundlegender Bedeutung und hängt eng mit der oben genannten topologischen Korrektheit des Graphen zusammen. Deutlich wird dies an folgendem Beispiel:
Obwohl die Station (rot) auf eines der Gleise gesnappt wurde, ist es unmöglich, die Station von Gleisstrang 1 aus zu erreichen. In Busnetzen tritt ein ähnliches Problem z.B. bei mehrspurigen Straßen auf, die jeweils als Einbahnstraße markiert sind. Fehlt die Station der Gegenrichtung, muss der Bus im Routing eventuell große Umwege nehmen, um in der richtigen Richtung die Station anfahren zu können.
Um diese Fälle abzudecken, wird aus der oben beschriebenen priority queue nicht nur die beste Station gewählt, sondern eine (fixe) Anzahl von möglichen Kandidaten. Auch bei diesen Kandidaten ist es möglich, auf Informationen aus OpenStreetMap zurückzugreifen.
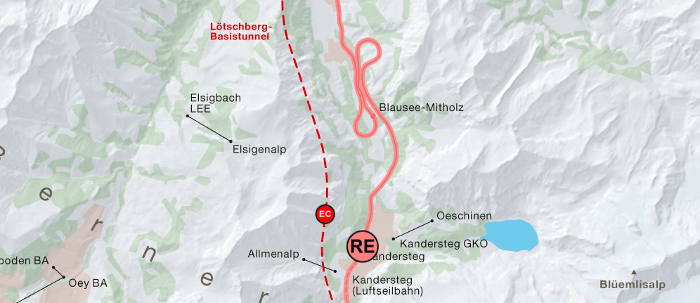
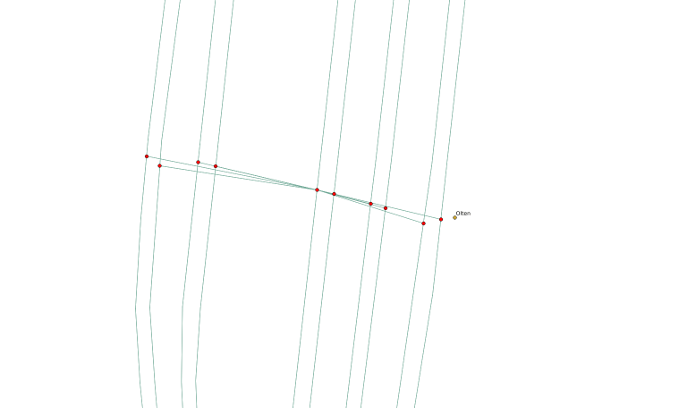
Diese Kandidaten werden nun mit einer Dummy-Kante mit der Primärstation (= die am besten gematchte Station) verbunden. Konkret heißt das z.B. im Schienennetz, dass wir Zügen erlauben, in Stationen die Gleise zu wechseln. Ohne diese Spezialkante wäre eine erfolgreiche Routensuche nur in den wenigsten Fällen möglich. Unten ist der Bahnhof Olten mit eingeblendeten Spezialkanten zu sehen.
2. Kürzester-Weg-Algorithmus
Nachdem der Graph erzeugt wurde, kann iterativ für jede im Fahrplan vorkommende Fahrt der kürzeste Weg zwischen je zwei aufeinanderfolgenden Stationen berechnet werden. "Kürzester Weg" ist dabei symbolisch zu verstehen - es handelt sich um den kostengünstigsten Weg. Die Berechnung der Kantenkosten folgt Heuristiken, von denen hier 2 kurz vorgestellt werden sollen.
Zugwendungen
Züge wenden nicht auf offener Strecke. Tun sie es doch, ist es mit erheblichem Aufwand verbunden. Einer der wichtigsten Heuristiken ist deshalb das Überwachen der Ein- und Austrittswinkel eines Fahrzeuges in einen Knoten und die Bestrafung, wenn dieser Winkel gewisse Werte überschreitet. Ein Sonderfall stellt die Zugwendung in Stationen selbst dar - hier ist sie üblich, jedoch trotzdem teuer.
Snappen auf passende OSM-Relationen
OSM hält für nahezu alle Verkehrsmittel eine Fülle von Relationen vor, aus denen meistens sogar die Liniennummern der Fahrzeuge hervorgehen, die die Wege innerhalb dieser Relation befahren. Um diese wertvollen Informationen während des Routings nicht zu verlieren, wird ein Weg stark belohnt, wenn er Kanten benutzt, die zu Relationen gehören die dem eigenen Verkehrsmittel und der eigenen Linienbezeichnung entsprechen. Durch dieses Vorgehen entsprechen gefundene Routen meist den bereits in OSM eingepflegten Liniennetzen.
3. Prüfen auf Plausibilität
Die gefundenen Fahrverläufe werden anschließend auf Realitätsnähe geprüft. Hierbei wird neben dem Verhältnis der Luftliniendistanz zur Distanz der gefundenen Strecke auch die Durchschnittsgeschwindigkeit berechnet, die ein Fahrzeug auf diesem Streckenverlauf haben müsste, um pünktlich am Ziel zu sein. Bei größeren Fehlern in der Wegfindung treten hier häufig Geschwindigkeiten > 1.000 km/h auf, so dass die Abweichung sicher erkannt und die Konfigurationsparameter ggfs. angepasst werden können.
4. Komprimierung und Vermeidung von Doppelberechnung
In ÖNV-Netzen teilen sich meist unzählige Fahrten eine gemeinsame Strecke. Es macht zum Beispiel wenig Sinn, für sämtliche Fahrten der Buslinie X in Richtung Y den Fahrtweg zu generieren, wenn dieser jedesmal exakt derselbe ist. Daher werden gefundene Wege nicht nur auf ihre Äquivalenz zu bisher gefundenen geprüft - es wird auch geprüft, ob für die Attribute einer Fahrt (Liniennummer, Ziel, Verkehrsmittel) und den Stationsverlauf bereits ein Shape vorliegt. Dieses Prinzip wird weitergeführt, um auch zusammenhängenden Untermengen (= zusammenhängende Teilstrecke) von Shapes nicht doppelt halten zu müssen. Folgt z.B. eine Linie meist dem Stationsverlauf A-B-C-D-E-F und ist für diesen Stationsverlauf bereits ein Shape gefunden worden, so wird einem "Ausreißer" derselben Linie der nur dem Stationsverlauf B-C-D-E folgt, dasselbe Shape zugewiesen. Außerdem wird anhand der Stationsfolge, des Fahrzeugtyps und der Linienbezeichnung versucht, bereits gefundene Shapes einem Fahrzeug zuzuordnen ohne einen shortest-path zu berechnen.
Ergebnisse
Mit dem oben beschriebenen Vorgehen haben wir die Fahrtwege des kompletten ÖNV-Netzes (zu Land und zu Wasser) von Deutschland und der Schweiz berechnet. Die Ergebnisse sind (bis auf das aktuell wegen noch nicht vorliegender Fahrplandaten für das Jahr 2015 fehlende deutsche Netz) live auf http://tracker.geops.de zu betrachten.
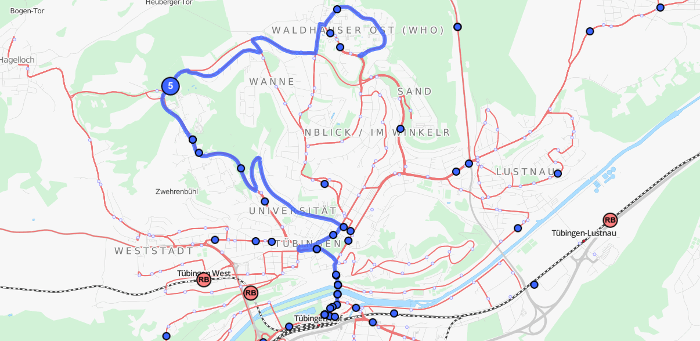
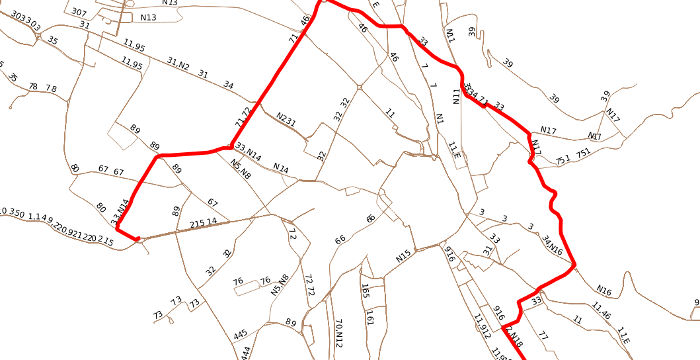
Auch die Generierung und Ausgabe des gesamten, mit fahrplanmäßigen Linienbezeichnungen versehenen Nahverkehrsnetzes einer Region oder eines Landes ist möglich. Das untenstehende Bild zeigt als Zusammenstellung der im Raum Zürich gefundenen Fahrtgeometrien das extrahierte Busliniennetz der Stadt.
Jede Geometrie stellt den mit dem Fahrplan korrelierten Fahrtverlauf von einer oder mehreren Buslinien dar. Anfragen der Form "welchen Fahrtweg nimmt die Buslinie 2, die am 22.8. um 19:20 an Station X startet?" sind problemlos zu beantworten.
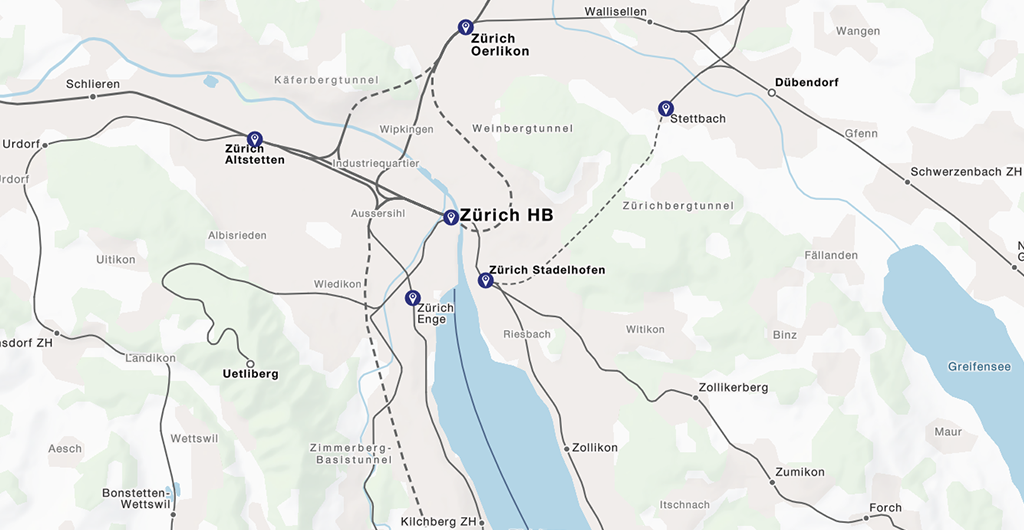
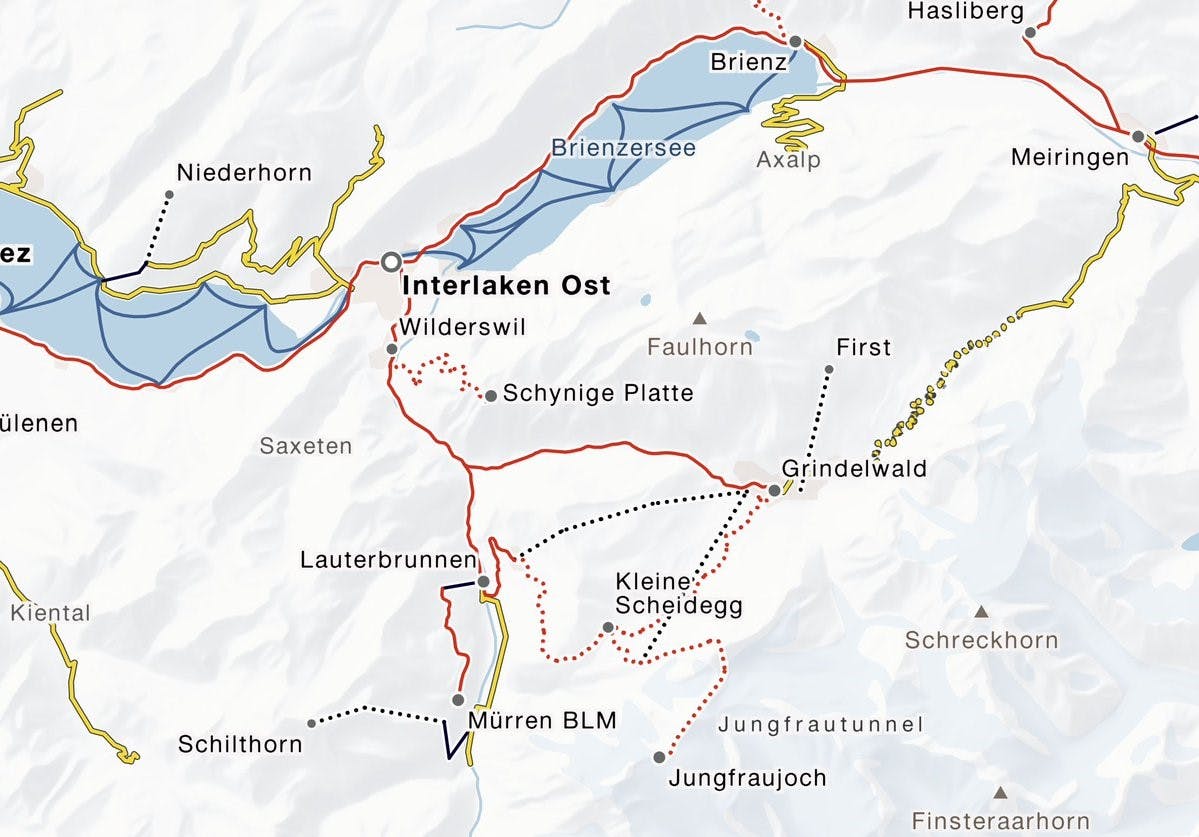
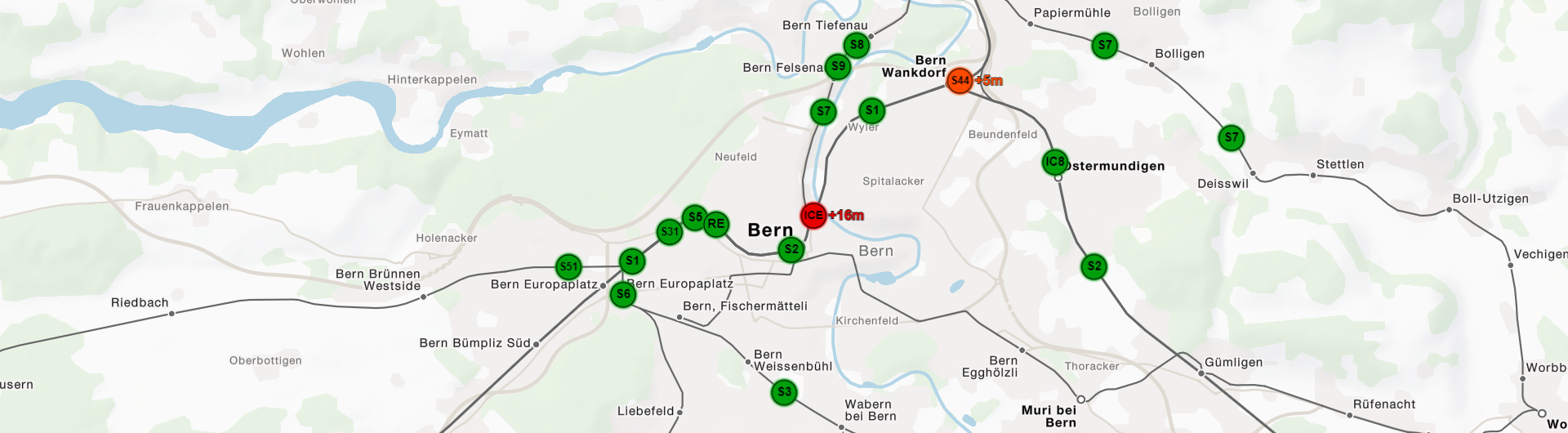
Die Fahrtverlaufsgenerierung ist dabei nicht auf OpenStreetMap als Ausgangsbasis beschränkt. Prinzipiell kann jede Datenquelle genutzt werden, aus der sich ein georeferenzierter Graph generieren lässt (z.B. Geometrien in einer PostGIS-Datenbank.) Ein Projekt, bei dem Fahrverläufe für verschiedene Generalisierungsstufen aus Shapefiles generiert wurden, stellt der Tracker auf den Trafimage-Karten der Schweizerischen Bundesbahn dar.


{kind=link}
{kind=link}
{kind=link}
{kind=link}